

もそもPythonとは
Pythonとはプログラミング言語のひとつで、他のプログラミング言語に比べシンプルな文法でプログラムを書けることが大きな特徴です。従ってPythonはC言語やJavaなどと比べると、プログラムの記述量を少なく抑えることが可能です。
さらに{}(波かっこ)は使わずインデントで処理のまとまりを示すので、どこまでが1つのまとまりかを直感的に把握しやすいという利点もあります。
このような理由からプログラミング入門者に適しているといわれているPythonですが、次のようにさまざまな場面で利用されています。
・アプリケーション開発
・Excelなどの作業の自動化
・Webスクレイピング
・データ分析・機械学習
このように多くの場面で利用されている理由のひとつとして、企業や個人が開発したライブラリ(機能を提供するプログラムをまとめたもの)が充実しているということがあげられます。
例えばデータ分析や機械学習などは、一見すると高度で複雑なプログラムが必要かのように思われますが、ライブラリを使用することで比較的シンプルなプログラムにすることが可能となります。
また、ここ数年でPythonの人気は急速に高まっています。
書店に行くとプログラミング言語の書籍はさまざまありますが、Pythonの書籍は他のプログラム言語と比べて数を増やしています。転職サイトやフリーランス向けのプログラミングの仕事情報を見ても、Pythonというキーワードをよく目にするようになりました。
これらの現象は、Pythonの高い人気を表しているといえます。Excelは昔からビジネスパーソン必須のツールですが、Pythonもそれと同じくらい必要とされ始めているといえるでしょう。
データ構造の異なるファイルを1つにまとめる
さて、いよいよ本題に入ります。
全3回のうち1回目である今回は、形式が異なる複数のExcelファイルを、Pythonを使って1つに連結する方法を紹介します。
業務で複数の部署からExcel ファイルを集めて集計することになったが、いざファイルを集めてみると、それぞれの表の形式が微妙に違っていた、なんてことはよく聞く話です。
列名が異なっていたり、列の順番が変わっていたりした場合、機械的に連結したらめちゃくちゃなデータになってしまいます。
例えば、以下のようにいくつかの支店のExcelファイルを集めて連結しようとしたところ、列の並びがバラバラになっていたとします。
(外部配信先では画像や図表等を全部閲覧できない場合があります。その際は東洋経済オンライン内でお読みください)
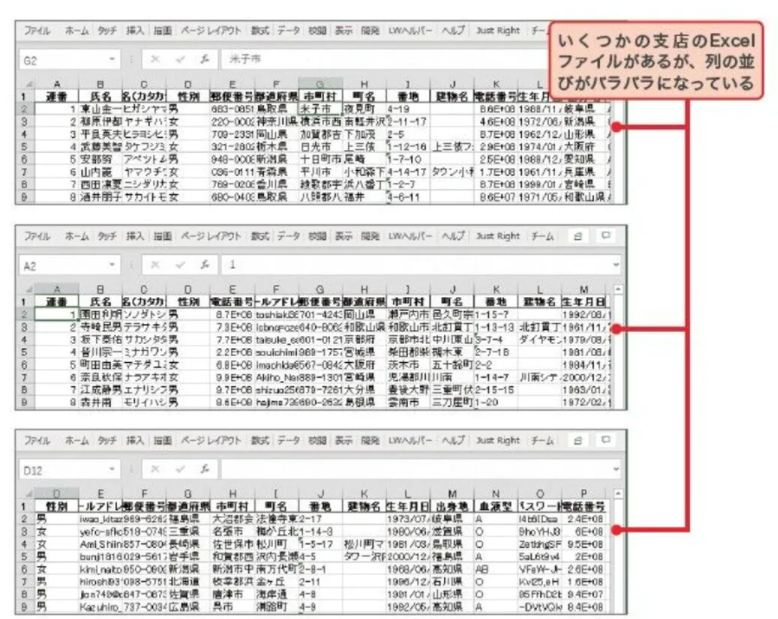
ますは今回紹介するPythonプログラムがどのように働くのかを見せましょう。
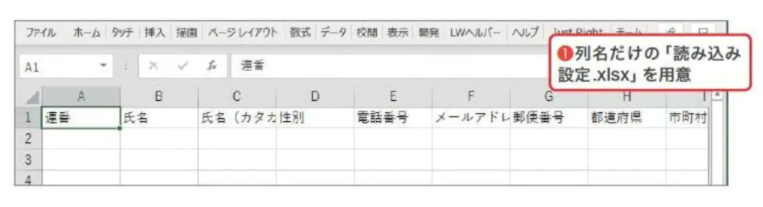
①はじめに、仕上がりの列の並びを指定する「読み込み設定.xlsx 」を用意します。
②続いて、Pythonプログラムを実行します。
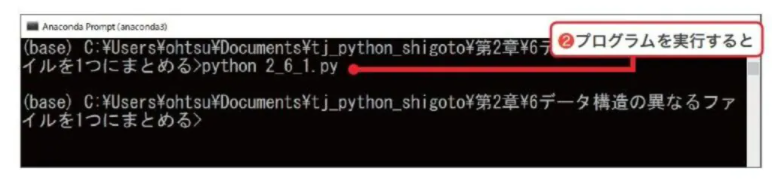
③すると以下の通り、各ファイルが連結されたExcelファイル(「統合表.xlsx」)が作成されます。
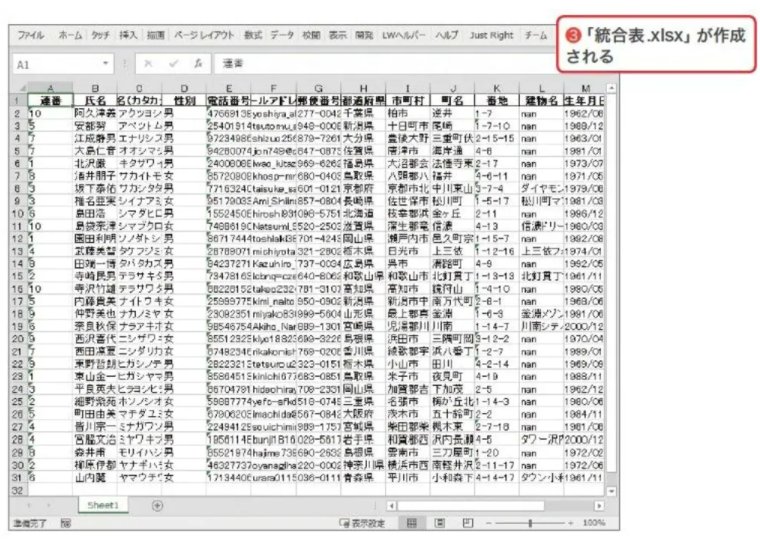
サンプルプログラムの全体像
②で実行した、データ構造の異なるファイルを1つにまとめるためのプログラムは次の通りです。
「長いなぁ」と思うかもしれませんが、「#」ではじまる行はプログラムではなくコメント文を表しているので、実際のプログラムはこの半分程度の行数になります。
なお、本プログラムはPython実行環境としてAnaconda(アナコンダ)の使用を前提としています。Anacondaは https://www.anaconda.com/products/individual からインストール可能です。
02 import pandas as pd
03 import glob
04 # 設定ファイルの読み込み
05 cols = pd.read_excel("読み込み設定.xlsx")
06 # 統合したデータを保存するリスト
07 result_list = []
08 # ◯◯支店.xlsx のファイル名を取り出すループ
09 for input_file in glob.glob("*支店.xlsx"):
10 df = pd.read_excel(input_file, dtype='object', engine="openpyxl")
11 # 1 行ずつExcel ファイルを読み込む
12 for index, row in df.iterrows():
13 # 作業用リスト
14 work = []
15 # 設定ファイルの列名を取り出すループ
16 for col in cols:
17 # 指定した列の情報がある場合
18 if col in df.columns:
19 work.append(str(row[col]))
20 # データがない場合は空のデータを追加する
21 else:
22 work.append("")
23 # 列の並びを整えて行を追加する
24 result_list.append(work)
25 # 出力用データの作成
26 df = pd.DataFrame(result_list, columns=cols.columns)
27 # ふりがなで並べ替え
28 df_result = df.sort_values(["氏名(カタカナ)"])
29 # Excel 形式で書き出し
30 with pd.ExcelWriter("統合表.xlsx") as writer:
31 df_result.to_excel(writer, index=False)
まず05行目で、①で作成した「読み込み設定.xlsx」を読み込み、DataFrameオブジェクト(表形式のデータ)を変数cols に入れます。
09行目ではglob関数を使い、「*支店.xlsx」というパターンに合うファイルの一覧を取得します。ただの「*.xlsx」というパターンだと「読み込み設定.xlsx」なども読み込んでしまうため、ファイル名の末尾が「支店」であることもパターンに入れています。
12行目のループで、Excelファイルからデータを1行ずつ取り出し、16行目の一番内側のループで列の順番をそろえる処理を行っています。この部分についてはこのあと説明します。
最後に、連結したファイルをDataFrameオブジェクトにし、それをto_excelメソッドで保存します。なお、今回のサンプルは名簿なので、並べ替えを行うsort_valuesメソッドを使って昇順に並べ替えています。
「読み込み設定.xlsx」にそろえて列順を変える
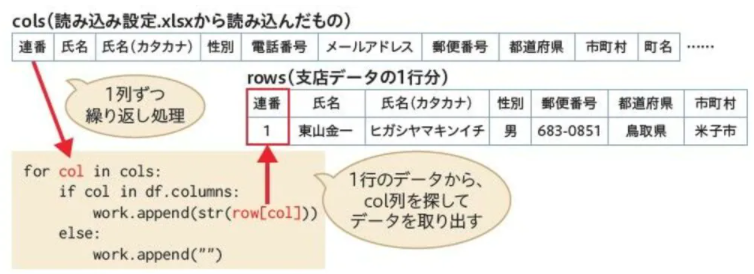
では、16~22行目に書かれている、いちばん内側のループを見ていきましょう。
ここでは「読み込み設定.xlsx」のデータを列ごとに分割し、それに対して繰り返し処理をしています。そのため、列の順番は「読み込み設定.xlsx」にそろうことになります。
ただし、支店のデータの中に「読み込み設定.xlsx」の列に相当するデータがない場合もありえます。具体的には、「横浜支店.xlsx」にはパスワード列がありません。そのため、該当する列があるかどうかを18行目のif文とin演算子でチェックし、ある場合は2重リストに追加し、ない場合は空文字列("")を追加しています。
2重リストにデータを追加する19行目の部分も要注目です。変数colには「読み込み設定.xlsx」から取り出した列名、変数rowには各支店のExcelファイルから取り出した1行分のデータ(Seriesオブジェクト)が入っています。
そこで「row[col]」と書くと、支店データの中から特定の列名のデータを取り出すことができるのです。あとは2重リストにappendメソッドで追加するだけです。
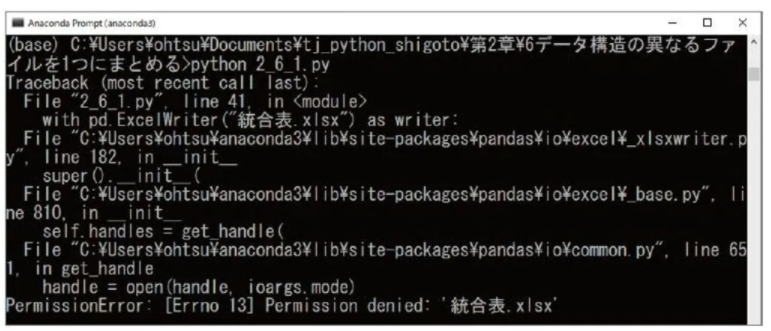
ちなみに、書き込み先の「統合表.xlsx」をExcelで開いた状態でプログラムを実行すると、「PermissionError(ファイルのアクセス許可のエラー)」が発生します。ファイルを閉じてから実行するよう注意してください。
まずは実行してみよう
Pythonに興味があっても初めてだという方は、まず今回紹介したプログラムを動かして、Pythonの便利さを体感してみるといいでしょう。
次に、プログラムの説明を読みながら中身を眺めてみて「この行は何をしているか?」をなんとなく理解したうえで、ご自身の仕事を効率化するものに書き換えていくことをおすすめします。
コメントをお書きください